返回博客
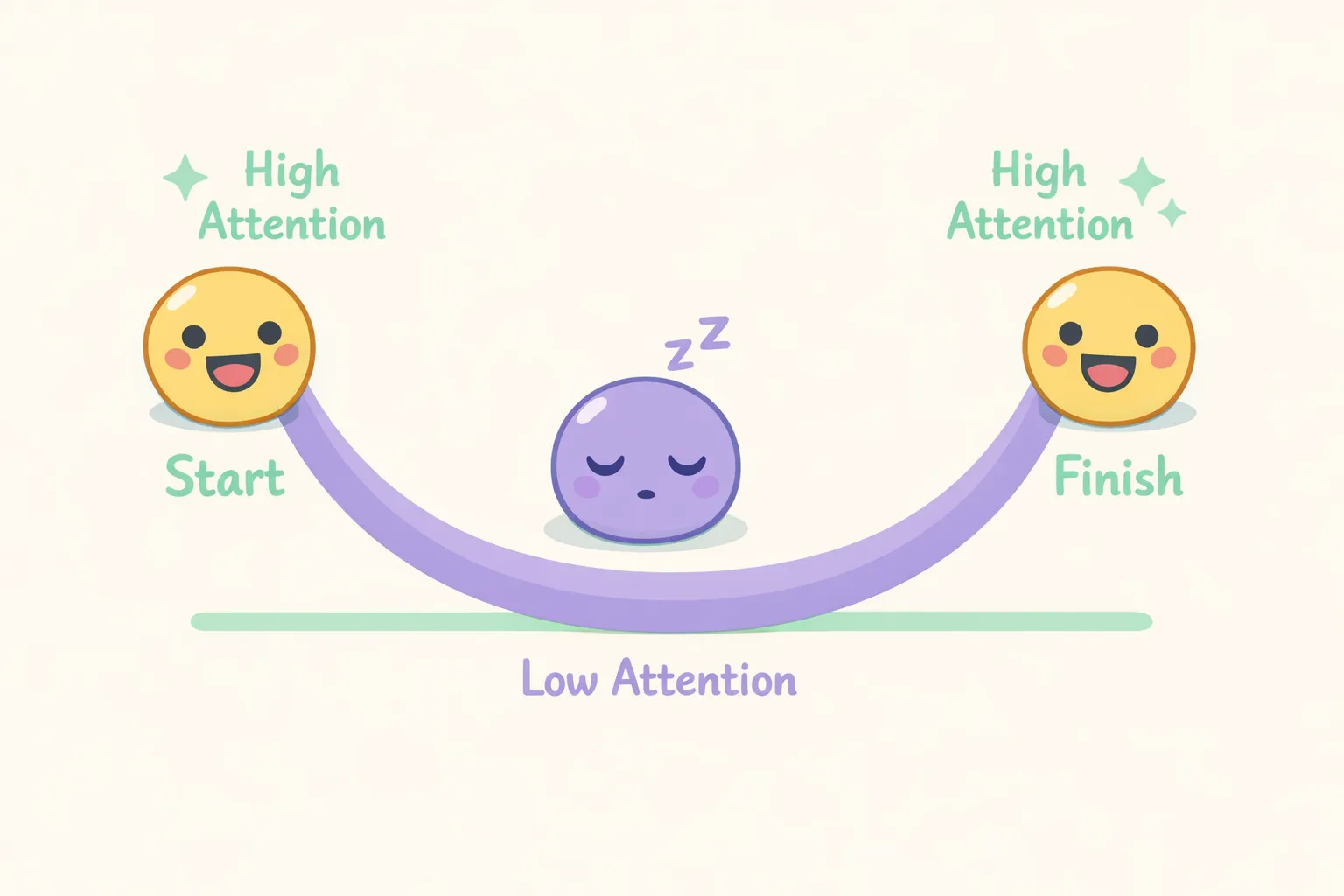
U 形曲线,展示 AI 注意力在上下文开头和结尾最高,中段最低 
一份交接说明从一个对话气泡递交到另一个全新的对话气泡
如何高效使用上下文窗口:别再让 AI 犯糊涂
AI 不是坏了,只是负担太重。学会识别上下文过载的预警信号,掌握五种实用策略,让对话始终走在正轨上。
你已经和 ChatGPT 聊到第二十条消息。你给过它项目简介、三轮反馈,还有一整套详细的需求清单。然后你随口追问一个简单的问题——它的回答却把你们之前讨论过的一切忘得一干二净。就像跟一个突然失忆、想不起过去一小时聊过什么的人对话。
你没有想多。AI 没坏,你也没做错什么。你只是撞上了使用 AI 助手时最容易被误解的环节之一:上下文窗口。
上下文窗口就是 AI 的工作记忆——它在任意时刻能「看见」并参与推理的文字总量。就像一个同事的脑子里同时装不了太多细节一样,AI 也有它的上限。一旦超过这个上限,问题就会以可预测的方式开始浮现。
下面就告诉你怎么识别 AI 已经「超载」,以及该怎么应对。
AI 为什么会在对话中途变糊涂
把上下文窗口想象成一块白板。你输入的每一个字——你的问题、AI 的回答、你贴进去的文档——都会被写到这块白板上。AI 每次回复时,都会把整块白板从头读一遍。
问题是,这块白板大小是固定的。一旦写满,旧内容就会被擦掉或压缩,腾地方给新消息。AI 不会主动告诉你这件事正在发生,它只会开始表现得「怪怪的」。
不同的 AI 工具,白板大小也不一样:
- ChatGPT(GPT-5): Plus 用户 12.8 万个 token,通过 API 最多可达 40 万个
- Claude: 标准为 20 万个 token,企业用户最高可达 100 万个
- Gemini: 搭配 Gemini 3 Pro 时最高可达 200 万个 token
一个 token 大约相当于四分之三个英文单词。所以 12.8 万个 token 大约是 9.6 万词——听上去够用了,可一旦你和它来回长聊,再贴上几份文档,这点额度会比你想象中消耗得快得多。
但这里有个大多数指南都不会提的关键点:官方标的上限并不是实际可用的上限。 根据 All About AI 的研究,模型的表现往往在远未到上限时就开始下降。比如 GPT-4 Turbo,虽然官方支持 12.8 万个 token,但在大约 3.2 万个 token 之后,准确率就已经开始打折扣。
「中段失忆」问题
就算你还在上下文容量之内,还有另一个问题:AI 模型并不会对上下文窗口里的所有内容一视同仁。
斯坦福大学研究人员的一项里程碑式研究发现,语言模型最擅长利用输入开头和结尾的信息。中间部分呢?它们处理得很费劲。研究人员把这种现象称为「迷失中段」(lost in the middle)效应。
在他们的实验中,当关键信息被埋在上下文中段、而不是放在开头或结尾时,GPT-3.5-Turbo 正确回答问题的能力下降了 20% 以上。
这就形成了一条 U 形的注意力曲线。AI 会重点关注你最早的几条消息和最近的几条消息,但靠前的中段内容权重会降低。倒不是说 AI 看不到这部分信息——而是模型的架构本身就更倾向于偏向某些位置。
实用建议: 把最重要的信息放在 prompt 的开头,或者在结尾再重复一遍。别想当然地以为 AI 还记着你六条消息之前提到的那个关键细节。
AI 开始「掉线」的预警信号
在 AI 完全跑偏之前,它通常会先露出一些预警信号。早一点发现这些信号,就能在浪费时间陷入混乱对话之前及时纠偏。
反复打转: AI 开始用稍微不同的措辞重复同样的建议,就像一个忘了自己已经讲过那个故事的朋友。
忽略已知细节: 你之前提过的事实——比如项目截止日期、某个具体限制——好像从未被提起过一样被忽略掉了。
回答变得空泛或跑题: 它不再贴着你的具体情境作答,回答变得通用,像是发给谁都行。
前后矛盾: AI 给出的建议和它早前说过的话直接打架,却完全没意识到自己改口了。
指令失忆: 你让它按某种格式或角色来回应,它确实照做了几条消息,然后悄无声息地恢复了默认风格。
只要你发现其中任何一种迹象,说明上下文窗口已经开始拥挤了。该出手了。
让 AI 不跑偏的五个策略
你没法把上下文窗口扩容,但可以更聪明地使用它。下面是五个真正管用的策略。
1. 开门见山,先抛主线
别把你的核心需求埋在一段段背景介绍下面。先说你想要什么,再补充上下文。AI 最关注的就是开头——把这块「黄金位置」留给最关键的内容。
不要这样写:
试着这样写:
我已经在这个项目上忙了三个月。一开始我们是另一种思路,但用户测试之后做了大调整。利益相关方对时间表有一些具体顾虑。我需要写一封进度更新邮件……
试着这样写:
我需要给利益相关方写一封项目进度更新邮件。关键背景:因为项目中途调整方向,我们比原计划晚了两周。语气要诚实但有信心。
2. 边聊边总结
长对话会积累各种「噪音」——离题、被否掉的想法、试探性的来回讨论。你可以隔一段时间让 AI 汇总一下到目前为止的关键决定,或者由你自己来做总结。
可以这样说:
继续之前,我先把目前定下来的几点梳理一下:
- 目标受众:小企业主
- 语气:专业但平易近人
- 核心信息:产品能节省开发票的时间
现在,我们来写第一段。
这相当于用真正重要的内容把上下文「重置」一遍,让 AI 集中在当前优先事项上,而不是被早先的支线话题牵着走。
3. 适时果断地另开新对话
有时候,最好的解决办法就是另开一个对话。如果你要切换话题、处理一项不同的任务,或者当前的对话已经一团乱,那就开一个新会话。
开新对话时,只把真正必要的内容带过去。写一份简短的「交接说明」,把关键背景浓缩进去——就像把一份项目摘要交给新加入的同事,而不是把过去一个月的所有邮件都甩给他。
示例交接说明:
项目:重新设计电商网站的结算流程
目标:把购物车放弃率降低 15%
限制:必须在移动端可用,不能更换支付服务商
已做决定:采用单页结算,顶部带进度条
当前任务:撰写订单确认页的文案
如果你发现自己在反复写类似的交接说明——只是换一下项目名称或任务描述——那就考虑把它们存成模板。像 PromptNest 这样的工具支持你把这些说明保存下来,并加入诸如
{{project_name}}、{{current_task}} 这样的变量,几秒钟就能填好空,复制出一段可直接拿去用的上下文重置文案。4. 用清晰的结构组织内容
AI 看到的所有内容都是一整面「文字墙」。加一点结构——标题、项目符号、带标签的小节——能帮它分清哪些是背景信息,哪些才是真正要做的任务。
用分隔符把不同部分隔开:
## 背景
我们是一家面向营销团队的 B2B SaaS 公司。
## 当前情况
试用转付费的转化率是 8%。行业平均水平是 12%。
## 任务
请提出三套提升试用转化率的邮件序列方案。
## 限制
- 每封邮件不超过 150 词
- 不使用任何折扣优惠
根据 Anthropic 的上下文工程指南,结构化的输入能帮助模型区分背景信息和实际任务,从而减少混淆。
5. 只给真正相关的上下文
上下文不是越多越好。明明只需要一小段,却把整份文档都塞进去,反而可能拖垮效果。AI 可能会抓着无关的细节不放,或者被一些枝节信息带跑。
在贴一份长文档之前,先问自己一句:要回答这个问题,AI 真正需要看的是哪几段?通常情况下,一段精挑细选的摘录,比整份文件更管用。
正如 Prompt Engineering Guide 所说:「一段简洁的摘要,胜过原始数据的堆砌。让你的上下文既有信息量,又紧凑紧实。」
什么时候该另开新对话
开新会话总让人感觉像在丢进度,但有时候这反而是最快的前进方式。判断标准如下:
这些情况下应该开新对话:
- 你要切换到完全不同的话题或任务
- AI 同时出现了多种预警信号(前后矛盾、忘记指令、回答空泛)
- 你们已经原地打转好几条消息,毫无进展
- 对话里堆满了被否掉的想法和支线讨论
这些情况下应该继续在当前对话里聊:
- 你正在围绕同一份内容反复打磨
- AI 仍然能准确引用前面的上下文
- 你在已有产出的基础上继续推进(修改稿件、扩展提纲)
目标不是回避长对话——而是回避杂乱的对话。一段聚焦的 30 条消息对话,完全可以正常运行;而一段四处游走、塞满 15 条支线消息的对话,可能已经在制造问题了。
搭一套属于自己的工作系统
高效使用上下文窗口不是一次性的修补——它是一种习惯。那些总能从 AI 助手身上稳定拿到好结果的人,并不一定更聪明,也不一定技术更强,他们只是学会了顺着这些限制做事,而不是和它们硬碰硬。
先从识别预警信号开始。一旦察觉,就尝试用上面的某种策略去应对。慢慢地,你会形成一种直觉:什么时候该让它总结,什么时候该重新组织结构,什么时候该干脆开个新对话。
等你摸索出一种真正好用的上下文结构——一份带来好结果的交接模板,或者一种能让 AI 始终在线的 prompt 格式——别让它湮没在聊天记录里。把它存到一个之后还能找得到的地方。
如果你想要一个专门为此打造的工具,PromptNest 是一款原生 Mac 应用,在 Mac App Store 上一次性付费 $19.99——没有订阅、不用注册账号,所有数据本地运行。你可以按项目整理自己最得力的 prompt 和交接模板,为会变化的部分加上变量,然后通过键盘快捷键在任意应用里随时调用。再也不用每次都凭记忆把同样的上下文重写一遍。
AI 的记忆有边界,你的不必有。