Bien utiliser la fenêtre de contexte : arrêtez de perdre votre IA
Votre IA n'est pas en panne, elle est saturée. Repérez les signes d'une surcharge de contexte et appliquez cinq stratégies concrètes pour garder vos conversations sur les rails.
Vous en êtes à votre vingtième message dans une conversation avec ChatGPT. Vous lui avez transmis le brief du projet, trois séries de retours et une liste détaillée d'exigences. Puis vous posez une simple question de relance — et la réponse ignore complètement tout ce que vous venez de discuter. Comme si vous parliez à quelqu'un qui aurait soudain oublié la dernière heure d'échanges.
Ce n'est pas dans votre tête. Votre IA n'est pas cassée et vous n'avez rien fait de travers. Vous venez juste de buter sur l'un des aspects les plus mal compris du travail avec un assistant IA : la fenêtre de contexte.
La fenêtre de contexte, c'est la mémoire de travail de l'IA — la quantité de texte qu'elle peut « voir » et exploiter à un instant donné. Comme un collègue qui ne peut garder qu'un certain nombre de détails en tête à la fois, l'IA a ses limites. Si vous les dépassez, les choses dérapent de façon prévisible.
Voici comment repérer une IA saturée et ce que vous pouvez y faire.
Pourquoi votre IA s'embrouille en cours de conversation
Imaginez la fenêtre de contexte comme un tableau blanc. Tout ce que vous tapez — vos questions, les réponses de l'IA, les documents que vous collez — vient s'écrire sur ce tableau. À chaque réponse, l'IA relit l'ensemble.
Le problème ? Le tableau a une taille fixe. Quand il est plein, le contenu ancien est effacé ou compressé pour faire de la place aux nouveaux messages. L'IA ne vous prévient pas. Elle se met simplement à se comporter bizarrement.
Chaque outil d'IA a son propre format de tableau :
ChatGPT (GPT-5) : 128 000 tokens pour les abonnés Plus, jusqu'à 400 000 via l'API
Claude : 200 000 tokens en standard, jusqu'à 1 million pour les comptes entreprise
Gemini : jusqu'à 2 millions de tokens avec Gemini 3 Pro
Un token correspond à peu près à trois quarts de mot. 128 000 tokens représentent donc environ 96 000 mots — ce qui semble énorme jusqu'à ce qu'on réalise qu'une longue discussion entrecoupée de quelques documents collés peut grignoter ce budget bien plus vite qu'on ne le croit.
Mais voici le piège que la plupart des guides oublient de mentionner : la limite annoncée n'est pas la limite utile. D'après une étude de All About AI, les performances chutent souvent bien avant le maximum théorique. GPT-4 Turbo, par exemple, perd en précision dès 32 000 tokens environ — alors qu'il peut techniquement en gérer 128 000.
Le problème du « lost in the middle »
Même quand vous restez sous la limite de contexte, il y a un autre souci : les modèles d'IA n'accordent pas la même attention à tout ce qui se trouve dans leur fenêtre.
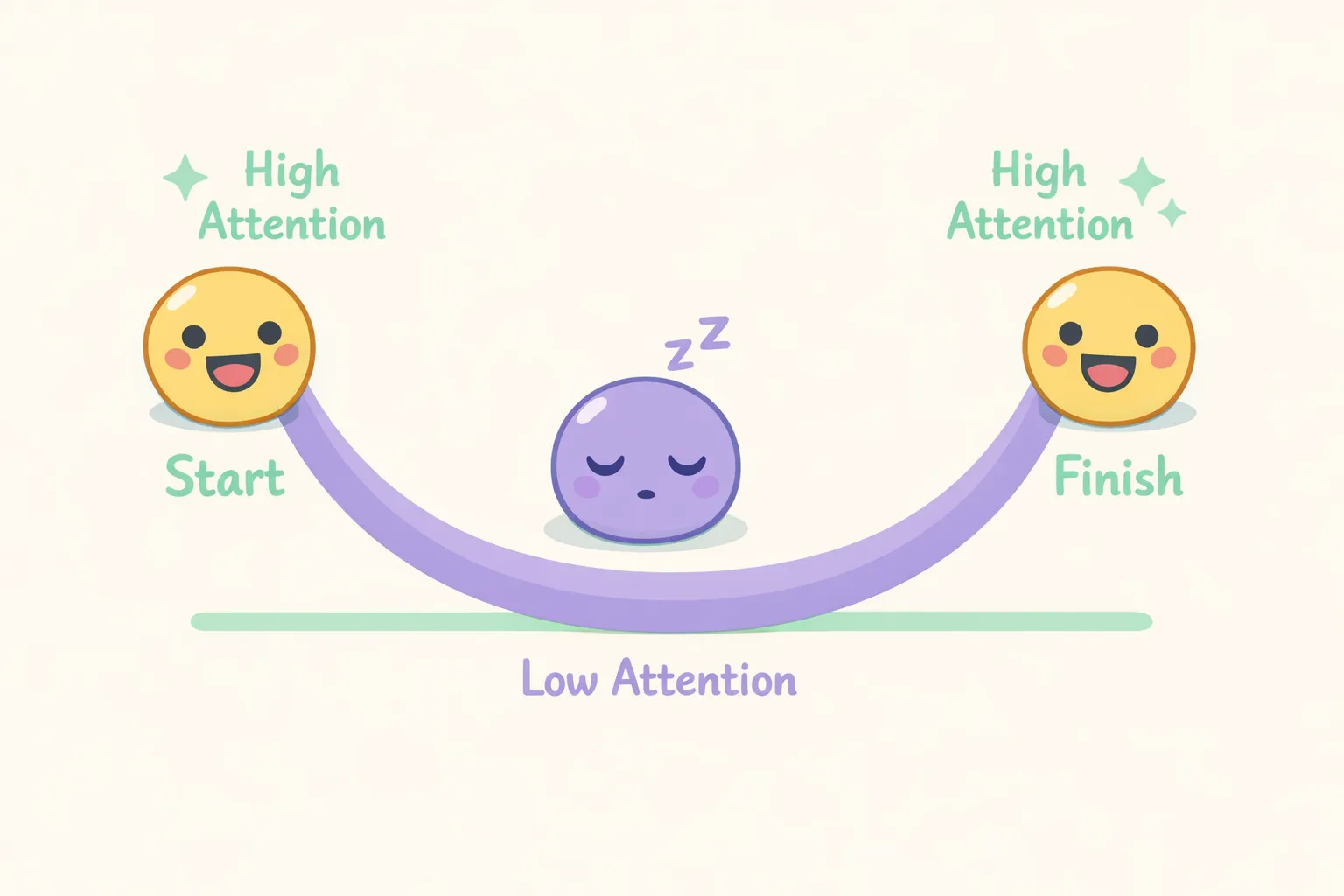
Une étude de référence menée par des chercheurs de Stanford a montré que les modèles de langage exploitent surtout les informations placées tout au début et tout à la fin de leur entrée. Ce qui est au milieu ? Ils ont du mal. Les chercheurs ont baptisé ce phénomène l'effet « lost in the middle » (perdu au milieu).
Lors de leurs tests, la capacité de GPT-3.5-Turbo à répondre correctement chutait de plus de 20 % lorsque l'information utile était enfouie au milieu du contexte plutôt qu'au début ou à la fin.
Courbe en U montrant que l'attention de l'IA est maximale au début et à la fin du contexte, et minimale au milieu
Cela dessine une courbe d'attention en U. L'IA suit de près vos premiers messages et vos plus récents, mais ce qui se trouve dans la première moitié — un peu plus loin que le début — pèse moins lourd. Ce n'est pas qu'elle ne voit pas l'information, c'est que l'architecture du modèle privilégie naturellement certaines positions.
À retenir : placez les informations les plus importantes au début de votre prompt, ou répétez-les vers la fin. Ne partez pas du principe que l'IA garde précieusement en mémoire ce détail crucial mentionné six messages plus tôt.
Les signaux qui montrent que votre IA perd le fil
Avant de partir complètement en vrille, l'IA donne presque toujours des signaux d'alerte. Les repérer tôt vous permet de corriger le tir avant de gaspiller du temps dans une conversation embrouillée.
Répétitions et boucles : l'IA reformule plusieurs fois le même conseil, comme un ami qui aurait oublié qu'il vous a déjà raconté cette histoire.
Détails oubliés : des éléments mentionnés plus tôt — une échéance de projet, une contrainte précise — sont ignorés comme s'ils n'avaient jamais existé.
Réponses génériques ou hors sujet : au lieu de s'appuyer sur votre contexte spécifique, la réponse devient passe-partout, applicable à n'importe qui.
Contradictions : l'IA propose une chose qui contredit directement ce qu'elle disait plus tôt, sans même signaler le changement.
Amnésie d'instructions : vous lui avez demandé de respecter un format ou un rôle précis, elle l'a fait quelques messages, puis elle revient discrètement à son comportement par défaut.
Si vous repérez l'un de ces signes, c'est que la fenêtre de contexte commence à être encombrée. Il est temps d'agir.
Cinq stratégies pour garder votre IA sur les rails
Vous ne pouvez pas agrandir la fenêtre de contexte, mais vous pouvez en tirer bien plus. Voici cinq stratégies qui fonctionnent vraiment.
1. Commencez par l'essentiel
N'enterrez pas votre demande sous des paragraphes de contexte. Dites d'abord ce que vous voulez, puis donnez les éléments d'appui. L'IA accorde le plus d'attention au début — réservez cet espace à ce qui compte vraiment.
Au lieu de :
Je travaille sur ce projet depuis trois mois. On était parti sur une autre approche, mais on a pivoté après les tests utilisateurs. Les parties prenantes ont des inquiétudes précises sur le calendrier. J'ai besoin de rédiger un e-mail de mise à jour...
Essayez :
J'ai besoin de rédiger un e-mail de mise à jour de projet pour les parties prenantes. Contexte clé : on a deux semaines de retard à cause d'un pivot en cours de route. Le ton doit être honnête mais rassurant.
2. Faites des points d'étape au fil de l'eau
Les longues conversations accumulent du bruit — digressions, idées abandonnées, allers-retours exploratoires. De temps en temps, demandez à l'IA de résumer les décisions prises jusqu'ici, ou faites-le vous-même.
Essayez quelque chose comme :
Avant de continuer, voici ce qu'on a décidé jusqu'ici :
- Cible : dirigeants de petites entreprises
- Ton : professionnel mais accessible
- Message clé : le produit fait gagner du temps sur la facturation
Maintenant, écrivons le premier paragraphe.
Cela « réinitialise » le contexte avec l'essentiel et aide l'IA à se concentrer sur les priorités du moment plutôt que sur d'anciennes digressions.
3. Repartez de zéro de façon stratégique
Parfois, la meilleure solution est d'ouvrir une nouvelle conversation. Si vous changez de sujet, passez à une autre tâche, ou que le fil actuel est devenu un capharnaüm, lancez un nouveau chat.
Quand vous le faites, n'emportez que l'essentiel. Rédigez un bref « document de briefing » qui capture les éléments clés — comme on confierait à un nouveau membre de l'équipe la synthèse du projet plutôt que tous les e-mails du dernier mois.
Exemple de briefing :
Projet : refonte du tunnel de paiement de notre site e-commerce
Objectif : réduire l'abandon de panier de 15 %
Contraintes : doit fonctionner sur mobile, on ne change pas de prestataire de paiement
Décisions prises : checkout sur une seule page, barre de progression en haut
Tâche en cours : rédiger le texte de la page de confirmation
Un document de briefing transmis d'une bulle de chat à une nouvelle bulle de chat vierge
Si vous vous surprenez à rédiger les mêmes briefings encore et encore — en changeant juste le nom du projet ou la description de la tâche — pensez à les enregistrer comme modèles. Des outils comme PromptNest vous permettent de stocker ces briefings avec des variables comme {{project_name}} et {{current_task}} : vous remplissez les blancs et vous copiez en quelques secondes une remise en contexte prête à l'emploi.
4. Structurez clairement
L'IA traite tout comme un mur de texte. Ajouter une structure — titres, listes à puces, sections étiquetées — l'aide à distinguer ce qui est du contexte de ce qui est la tâche réelle.
Utilisez des délimiteurs pour séparer les sections :
## Contexte
Nous sommes une entreprise SaaS B2B qui vend à des équipes marketing.
## Situation actuelle
Notre conversion essai-vers-payant est de 8 %. La moyenne du secteur est de 12 %.
## Tâche
Proposer trois séquences d'e-mails pour améliorer la conversion des essais.
## Contraintes
- Garder chaque e-mail sous 150 mots
- Pas d'offres de remise
D'après le guide d'ingénierie de contexte d'Anthropic, des entrées structurées aident les modèles à distinguer les informations de contexte de la tâche réelle, ce qui réduit la confusion.
5. Ne donnez que le contexte pertinent
Plus de contexte n'est pas toujours mieux. Coller un document entier alors qu'une seule section vous suffirait peut même nuire au résultat. L'IA risque de s'accrocher à des détails sans intérêt ou de se laisser distraire par des informations annexes.
Avant de coller un long document, posez-vous la question : de quelles parties précises l'IA a-t-elle réellement besoin pour répondre ? Bien souvent, un extrait bien choisi vaut mieux que le fichier complet.
Comme le résume le Prompt Engineering Guide : « Un résumé concis vaut mieux qu'un déversement de données brutes. Gardez votre contexte informatif, mais resserré. »
Quand ouvrir une nouvelle conversation
Repartir de zéro donne l'impression de perdre des acquis, mais c'est parfois le chemin le plus rapide. Voici quand le faire :
Ouvrez un nouveau chat quand :
Vous passez à un sujet ou une tâche complètement différents
L'IA cumule plusieurs signaux d'alerte (contradictions, instructions oubliées, réponses génériques)
Vous tournez en rond depuis plusieurs messages sans progresser
La conversation s'est chargée d'idées abandonnées et de digressions
Restez sur le chat actuel quand :
Vous itérez sur un même livrable
L'IA continue de citer correctement le contexte précédent
Vous construisez sur les sorties précédentes (peaufiner un brouillon, étoffer un plan)
Le but n'est pas d'éviter les longues conversations — c'est d'éviter les conversations encombrées. Un fil concentré de 30 messages peut très bien fonctionner. Un fil de 15 messages parsemé de digressions peut déjà poser problème.
Mettez en place un système qui vous suit
Bien gérer les fenêtres de contexte n'est pas une astuce ponctuelle, c'est une habitude. Les personnes qui obtiennent régulièrement de bons résultats avec les assistants IA ne sont pas forcément plus malines ou plus techniques. Elles ont juste appris à composer avec les limites au lieu de lutter contre.
Commencez par guetter les signaux d'alerte. Quand vous les repérez, testez l'une des stratégies ci-dessus. Avec le temps, vous développerez une intuition pour savoir quand résumer, quand restructurer et quand repartir de zéro.
Et le jour où vous trouvez une structure de contexte qui marche — un modèle de briefing qui donne d'excellents résultats, ou un format de prompt qui maintient l'IA sur la bonne voie — ne le laissez pas se perdre dans votre historique de discussion. Rangez-le quelque part où vous pourrez le retrouver.
Si vous cherchez une solution dédiée, PromptNest est une application Mac native, à $19.99 en achat unique sur le Mac App Store — pas d'abonnement, pas de compte, tout tourne en local. Vous organisez vos meilleurs prompts et modèles de briefing par projet, ajoutez des variables pour les parties qui changent, et accédez à tout via un raccourci clavier depuis n'importe quelle app. Plus besoin de réécrire de mémoire la même mise en contexte.
La mémoire de l'IA a ses limites. La vôtre n'a pas à les avoir.