返回博客
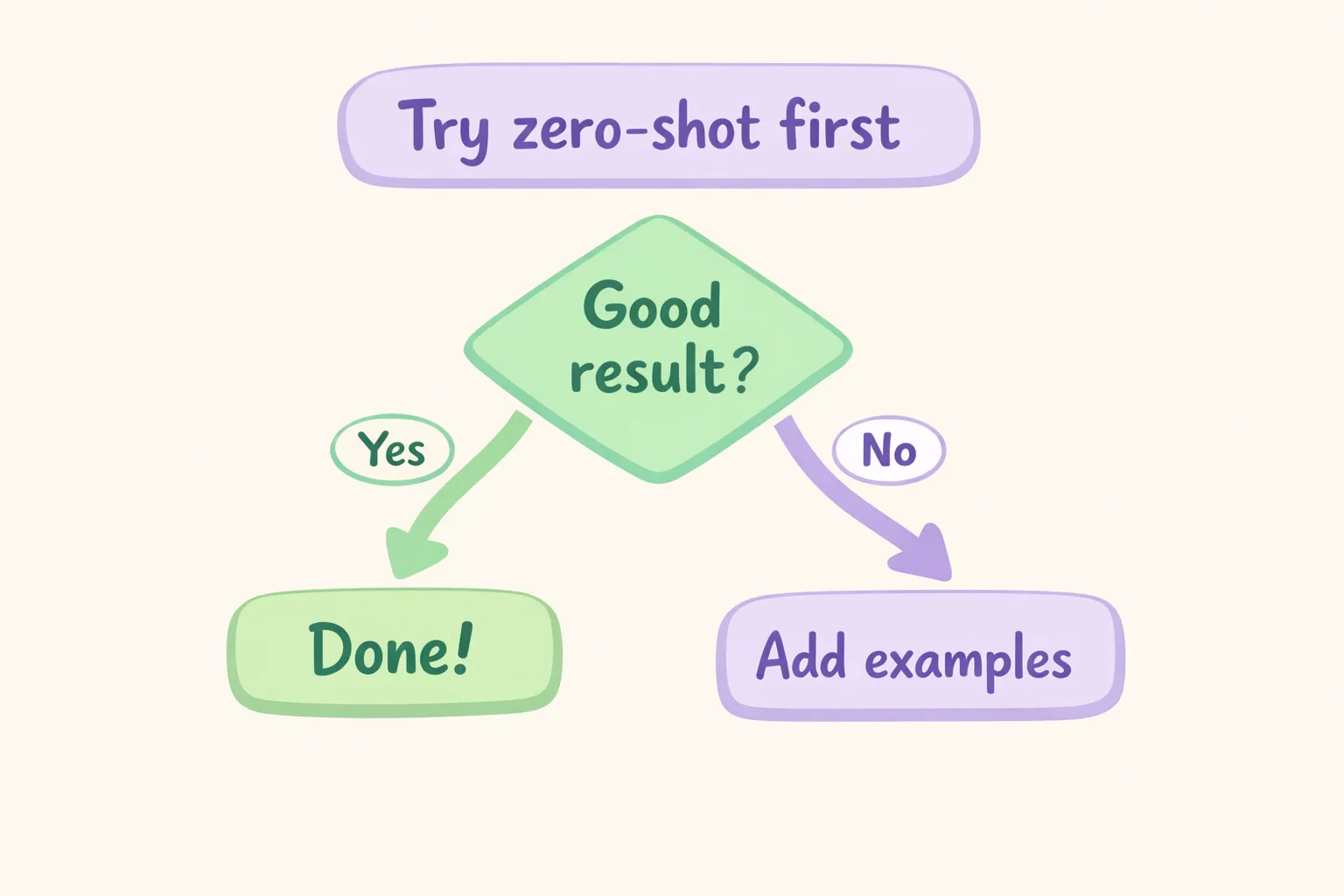
流程图,展示决策过程:先尝试零样本,评估结果,仅在需要时加入示例 
示意图:往提示中逐步添加示例卡片,前几张之后效果递减
少样本 vs. 零样本提示:什么时候该用哪一种
一份实用指南,帮你为任务选择合适的提示方式,附可复制的示例和简洁的决策框架。
你把一段提示词粘进 ChatGPT,输出结果……还行。但你也见过有人通过在提示中加入“示例”得到效果好得多的回答。你也该这么做吗?要加几个示例?这对你手头的任务真的有用吗?
这些问题经常冒出来,而那些术语也帮不上忙。“零样本”“少样本”“单样本”——听起来像是摄影词汇,而不是实用建议。这篇指南将抛开行话,给你一个清晰的决策框架,帮你判断该用哪种方式,并附上可以直接复制测试的完整提示。
零样本提示到底是什么
零样本提示,是指你给 AI 布置一个任务,但不展示任何你想要的示例。你描述需求,模型则依靠自身训练得到的知识去完成。
下面是一个用于总结会议的零样本提示:
请将以下会议记录总结为 3-5 条要点,涵盖会议中做出的关键决策。
会议记录:
{{meeting_notes}}
就这么简单。没有“好总结”的范例,也没有示范的输入输出。你完全相信模型自己理解什么是总结、什么是“关键决策”。对很多任务来说,这种方式效果出奇地好。
少样本提示到底是什么
少样本提示,是指在提示中加入 2-5 个示例,向 AI 展示你希望它遵循的模式。本质上你是在说:“我希望你这样处理”,然后再交给它真正的任务。
同样是会议总结的任务,加入示例后是这样的:
请将会议记录总结为 3-5 条要点,涵盖关键决策。
示例 1:
输入:“团队讨论了第三季度目标。Sarah 提议将销售目标提高 15%。Mark 不同意,认为按当前管线 10% 更现实。团队投票后定为 12%。同时决定将网站改版推迟到第四季度。”
输出:
- 第三季度销售目标增长定为 12%(在 15% 与 10% 提案之间折中)
- 网站改版推迟至第四季度
示例 2:
输入:“预算评审会议。当前支出超出预测 8%。CFO 建议将差旅预算削减 50%,并冻结新员工招聘 60 天。CEO 批准两项措施立即生效。”
输出:
- 差旅预算削减 50%(立即生效)
- 批准 60 天招聘冻结
- 应对 8% 的预算超支
现在请总结这条:
{{meeting_notes}}
注意区别。示例向模型清楚展示了你想要的格式(要点加括号补充上下文)、应包含的细节程度,以及如何处理多个决策。模型会在上下文中学到你的偏好——不需要任何微调。
两者关键差异一览
下面从最重要的几个维度对比这两种方法:
- 速度: 零样本更快。要处理的 token 更少,响应也更快。
- 成本: 零样本更便宜。按 token 计费,示例累积下来不便宜。
- 准备成本: 零样本几乎不需要。少样本则要找到或编写好的示例。
- 简单任务的准确度: 大体相当。现代模型对直白请求都能处理得不错。
- 复杂或定制任务的准确度: 少样本通常胜出。当你需要特定格式或专业术语时,示例能带来明显差别。
权衡一目了然:零样本更简单、更便宜,少样本则让你对输出有更多掌控。问题在于这种额外掌控值不值得。
什么时候零样本最合适
当任务正好是模型从训练中已经“掌握”的内容时,零样本提示就能发挥得最好。包括:
通用知识问题: 让模型解释、定义或提供事实信息。模型知道一份好的解释长什么样。
创意头脑风暴: 生成想法、起草初稿、罗列选项。这种场景你想要多样性,而不是固定模式。
常规摘要: 提炼文章、邮件或文档,且不要求特定格式。
翻译: 在模型训练过的语言之间转换文本。
简单分类: 将条目分到通俗的类别(正面/负面、紧急/不紧急),且类别本身一目了然。
创意头脑风暴: 生成想法、起草初稿、罗列选项。这种场景你想要多样性,而不是固定模式。
常规摘要: 提炼文章、邮件或文档,且不要求特定格式。
翻译: 在模型训练过的语言之间转换文本。
简单分类: 将条目分到通俗的类别(正面/负面、紧急/不紧急),且类别本身一目了然。
一个简单的判断标准:如果你能用大白话把需求说清楚,并且一个人不看示例就能听懂,那零样本大概率就够用。
什么时候少样本值得多花 token
当输出需要遵循模型仅凭说明无法推断的模式时,少样本提示就能发挥价值:
自定义格式: 当你需要特定结构的输出——含特定字段的 JSON、有固定列的表格、特定风格的要点列表。示例展示格式比文字描述更直观。
专属分类类别: 如果你要把客户邮件分到 “billing-question”“feature-request”“bug-report”“general-inquiry” 这类自定义类别,给每类配上示例能帮模型理解你的定义。
品牌语气或风格匹配: 想让 AI 写出公司现有内容的味道?给它看 2-3 个该风格的示例。“以专业又友好的语气写作”这种说法太空泛,示例则非常具体。
领域特定术语: 如果你的行业用的术语或缩写在别处含义不同,示例能教会模型理解你的语境。
边界情况和细微差别: 反讽、讽刺,或那些会让零样本绊倒的微妙差异。研究显示,少样本提示能显著改善对情感边界情况(如否定与反讽)的处理。
专属分类类别: 如果你要把客户邮件分到 “billing-question”“feature-request”“bug-report”“general-inquiry” 这类自定义类别,给每类配上示例能帮模型理解你的定义。
品牌语气或风格匹配: 想让 AI 写出公司现有内容的味道?给它看 2-3 个该风格的示例。“以专业又友好的语气写作”这种说法太空泛,示例则非常具体。
领域特定术语: 如果你的行业用的术语或缩写在别处含义不同,示例能教会模型理解你的语境。
边界情况和细微差别: 反讽、讽刺,或那些会让零样本绊倒的微妙差异。研究显示,少样本提示能显著改善对情感边界情况(如否定与反讽)的处理。
一项研究发现,对于 Twitter 情感分类,仅 20-50 个示例的少样本提示效果就接近基于 1 万多条数据微调的模型。这就是精挑细选的示例所带来的力量。
如果你发现自己开始为不同任务积累一整套少样本提示,PromptNest 这样的工具能帮你保存它们,并在内部内置
{{meeting_notes}} 这样的变量——复制时填空,整段提示就能直接粘贴使用。“先零样本,需要再升级”的工作流
下面这套实操方法既省时间又省 token:
第 1 步:先试零样本。 写一段清晰的提示,把任务说明白。要具体,但暂时不要加示例。
第 2 步:评估输出。 它给到你想要的结果了吗?满足就完事了。如果没有,找出哪里不对——是格式?语气?细节缺失?还是完全没理解任务?
第 3 步:有针对性地加示例。 编写 2-3 个示例,专门示范模型出错的那部分。如果是格式不对,就展示正确格式;如果是语气不对,就展示合适的语气。
第 2 步:评估输出。 它给到你想要的结果了吗?满足就完事了。如果没有,找出哪里不对——是格式?语气?细节缺失?还是完全没理解任务?
第 3 步:有针对性地加示例。 编写 2-3 个示例,专门示范模型出错的那部分。如果是格式不对,就展示正确格式;如果是语气不对,就展示合适的语气。
这套流程之所以重要,是因为你不再凭感觉判断要不要加示例——而是在弥补真实存在的缺口。有时候在零样本提示里加一句“让我们一步步思考”,就能解决推理问题,根本不需要示例。研究证实,在推理任务上,零样本思维链通常胜过少样本。
到底要给多少个示例
研究一致指出,对大多数任务来说,2-5 个示例是甜蜜点。数据告诉我们:
- 前 2-3 个示例带来的准确度提升最大
- 4-5 个之后回报急剧递减
- 太多示例反而可能拖累表现,引入相互冲突的模式
- 示例质量比数量更重要——三个出色的示例胜过十个平庸的
还有一个值得注意的发现是示例的顺序:多项研究表明,示例的排列顺序会影响结果,最佳顺序有时直接决定效果好坏。如果你的少样本提示效果不理想,先试着调换示例顺序,再考虑添加更多。
对大多数场景而言,先用 2 个示例。如果准确度还达不到要求,再补一个覆盖不同变体的示例。极少需要超过 4 个。
思维链:推理任务的折中之选
在数学、逻辑和多步问题上,还有第三种方法表现尤其出色:思维链提示。你不再展示输入-输出示例,而是要求模型“一步一步地思考”。
零样本思维链长这样:
一家商店有 45 个苹果。上午卖出 12 个,又收到 30 个的进货。下午又卖出 18 个。打烊时还剩多少个苹果?
让我们一步一步来推理。
就这一句简单的“让我们一步一步来推理”,就会促使模型展示推理过程,而不是直接抛出答案。在复杂推理上,这种做法常常优于零样本和少样本。
arXiv 的最新研究发现,对于 GPT-4 和 Claude 这类强模型,零样本思维链在推理任务上常常胜过少样本提示。示例反而可能限制模型的思路。
什么时候用思维链:
- 任务需要多个逻辑步骤
- 你需要模型解释推理过程(便于发现错误)
- 涉及数学、编程逻辑或分析类问题
- 你不仅想验证答案,还想检查模型的思路
可直接复制的完整提示示例
下面对真实任务并排展示这三种方式。所有提示都在 GPT-4 和 Claude 上测试过,可以直接使用。
任务 1:邮件语气分类
零样本版本:
请将以下客户邮件的语气分类为以下之一:frustrated、satisfied、neutral 或 urgent。
邮件:
{{email_text}}
语气:
少样本版本(更适合处理边界情况):
请将客户邮件语气分类为:frustrated、satisfied、neutral 或 urgent。
邮件:“我已经等了三周才收到订单。这太离谱了。我现在就要退款。”
语气:frustrated
邮件:“想说声谢谢——产品提前到货,用起来很棒!”
语气:satisfied
邮件:“你好,麻烦确认一下我的订单是否已发货?订单号 #12345。”
语气:neutral
邮件:“我们的系统宕机了,今天就需要替换件,不然合同就丢了。”
语气:urgent
邮件:{{email_text}}
语气:
少样本版本能帮模型理解你定义的边界。“urgent” 与 “frustrated” 之间容易模糊——示例让你的边界一清二楚。
任务 2:产品描述改写
零样本版本:
请将这段产品描述改写得更有吸引力、更突出用户收益。控制在 100 字以内。
原文:{{product_description}}
改写后:
少样本版本(更适合保持品牌语气一致):
请改写产品描述,让它更有吸引力、突出用户收益。请参照以下风格:
原文:“不锈钢水壶。容量 24 盎司。可保冷 24 小时。”
改写:“用我们这款时尚的 24 盎司不锈钢水壶,整天补水都不用愁。早上的咖啡到办公室时仍然温热,下午的水到健身房依旧冰凉。一只水壶,无限可能。”
原文:“无线耳机。8 小时续航。主动降噪。”
改写:“八小时不间断地享受你最爱的播客。我们的无线耳机屏蔽噪音,让你专注于真正重要的事——无论是深度工作、健身歌单,还是终于把那本有声书听完。”
原文:{{product_description}}
改写:
少样本版本传授的是一种特定的文案风格——以收益为导向、口语化、具体使用场景。零样本会给你一个改写,但不一定是你的风格。
任务 3:Bug 报告结构化
零样本版本:
请将这份 Bug 报告整理为结构化格式,包含:Summary、Steps to Reproduce、Expected Behavior 和 Actual Behavior。
Bug 报告:{{bug_report}}
少样本版本(更适合保持格式一致):
请将 Bug 报告整理为结构化格式。
输入:“我在尝试上传一个 PDF 时应用崩溃了。我当时在仪表板上,点击了上传,选了一个 5MB 的 PDF,结果应用直接关掉了。本应在我的上传列表里看到该文件,但整个应用直接崩了。”
输出:
**Summary:** 上传 PDF 文件时应用崩溃
**Steps to Reproduce:**
1. 进入仪表板
2. 点击上传按钮
3. 选择一个 PDF 文件(已用 5MB 文件测试)
**Expected:** 文件出现在上传列表中
**Actual:** 应用意外崩溃 / 退出
---
输入:{{bug_report}}
输出:
对于技术文档来说,一致性很关键。少样本版本能保证每份 Bug 报告都遵循相同的结构、相同的细节程度。
快速决策框架
面对一个新任务时,依次问自己这几个问题:
1. 任务是否直白且定义清晰? → 先用零样本
2. 是否需要模型不太可能猜中的特定格式? → 用少样本
3. 任务是否涉及多步推理? → 先试零样本思维链
4. 是否需要一致的品牌语气或专业术语? → 用少样本,并配上该语气的示例
5. 零样本已经达到 80% 的效果了吗? → 那就别折腾。多花三倍 token 追求完美不值得。
目标不是用上最花哨的技巧——而是高效地拿到好结果。零样本是默认选项。只在简单方法不够用时才增加复杂度。
把方法落到实处
把这些内化的最好方式就是动手实验。挑一项你经常做的任务——总结报告、起草邮件、整理反馈——把两种方式都试一遍。留意零样本在哪些地方力不从心,留意少样本在哪些地方真正带来差别。
一旦你找到了好用的提示,就把它们存到一个你真正能再次找到的地方。如果你正在积累带示例和变量的提示库,PromptNest 是一款原生 Mac 应用(在 Mac App Store 一次性 $19.99,无订阅、无账号、本地运行),可以让它们井井有条、随时可搜索,并通过键盘快捷键在任何应用中即调即用。再也不用在零散的笔记里翻找三周前写过的那条完美少样本提示。
从简单开始。需要时再增加复杂度。把好用的存下来。这就是全部策略。